Overview

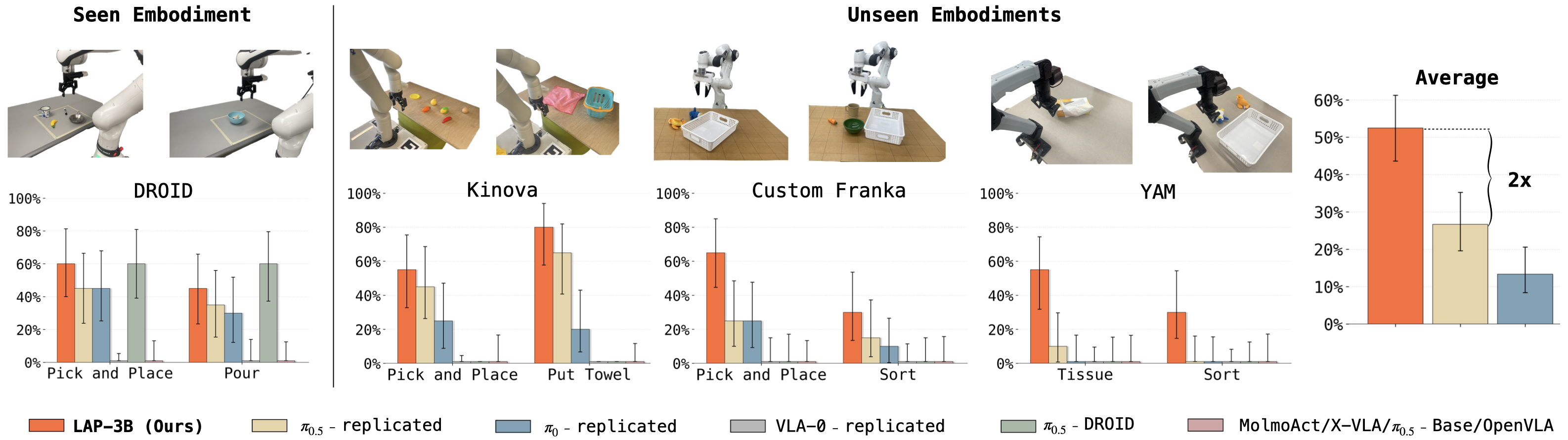
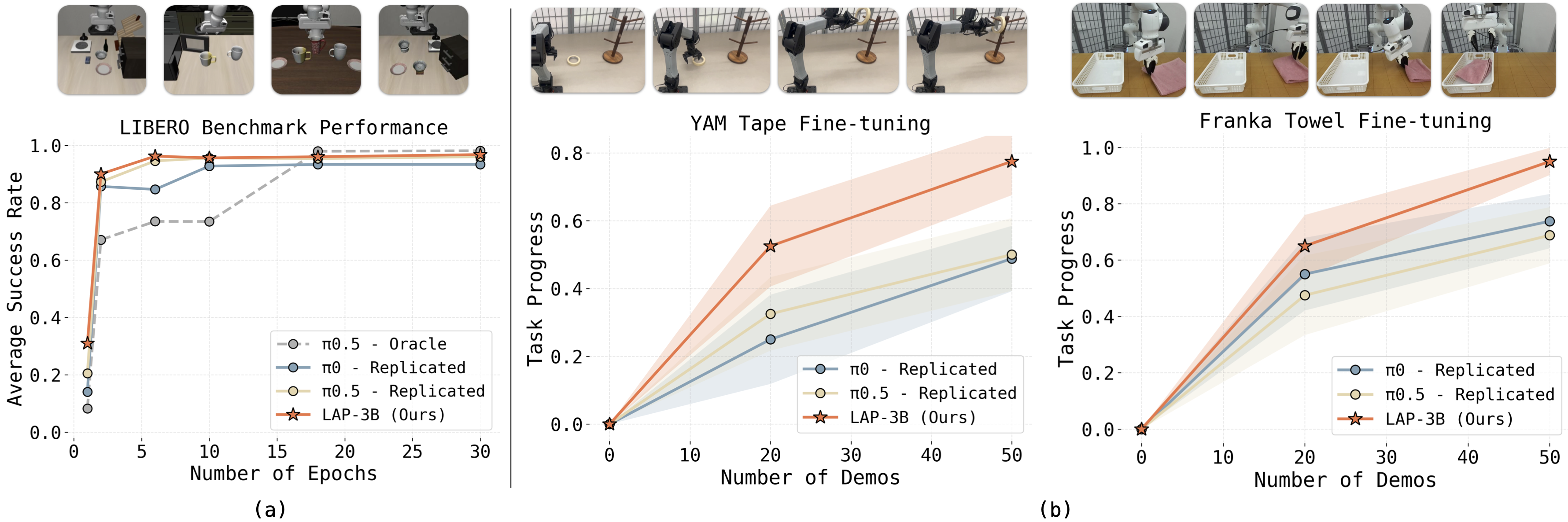
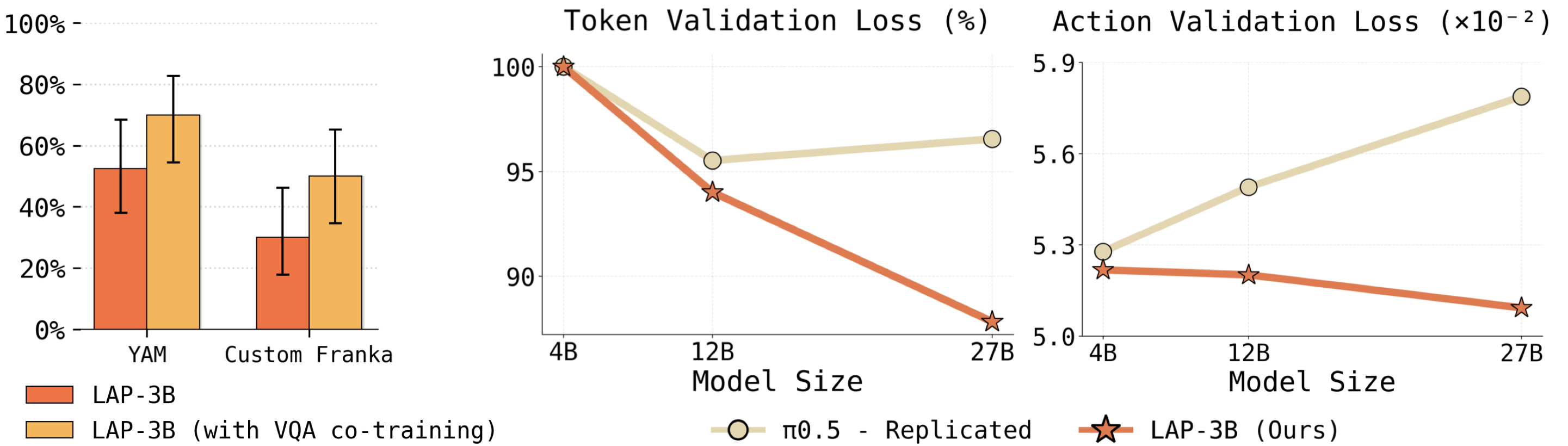
We introduce Language-Action Pre-training (LAP), a general VLA pre-training recipe that represents low-level actions in natural language to supervise a vision-language backbone, unifying action learning and VQA. We instantiate this approach as LAP-3B, the first VLA to demonstrate strong zero-shot transfer to novel embodiments. Compared to state-of-the-art VLAs, LAP-3B learns more generalizable embodiment representations and exhibits favorable scaling behavior.